支持向量机模型pytorch
通过5个条件判定一件事情是否会发生,5个条件对这件事情是否发生的影响力不同,计算每个条件对这件事情发生的影响力多大,写一个支持向量机模型pytorch程序,最后打印5个条件分别的影响力。
示例一
支持向量机(SVM)是一种监督学习模型,主要用于分类和回归分析问题。在SVM中,影响力或者重要性的概念并不像决策树中的特征重要性那样直接。SVM通过找到能够将不同类别的数据点分隔开的超平面来进行分类,而数据点距离这个超平面的远近(即间隔)决定了分类的置信度。
在SVM中,特征的影响力通常是通过模型的权重来间接体现的,这些权重在训练过程中被优化以最大化间隔。然而,需要注意的是,SVM的权重并不能直接解释为每个特征对最终决策的影响力,因为它们是在高维空间中同时优化得到的。
虽然PyTorch主要用于实现和训练神经网络,但我们仍然可以使用它来构建SVM模型。不过,通常情况下,SVM更倾向于使用像scikit-learn这样的库来实现,因为这些库为SVM提供了专门的优化算法和接口。
不过,如果坚持要使用PyTorch来实现SVM,并尝试从中提取特征的影响力,下面是一个简化的线性SVM实现示例,其中包含了训练完成后打印权重(作为影响力的一种近似)的步骤:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 假设我们有5个条件(特征)
num_features = 5
# 生成一些模拟数据
X, y = make_classification(n_samples=100, n_features=num_features, n_informative=num_features, n_redundant=0, random_state=42)
# 将数据转换为PyTorch张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y * 2 - 1, dtype=torch.float32) # 将标签转换为+1和-1 # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_tensor, y_tensor, test_size=0.2, random_state=42) # 定义线性SVM模型
class LinearSVM(nn.Module): def __init__(self, input_dim): super(LinearSVM, self).__init__() self.linear = nn.Linear(input_dim, 1) def forward(self, x): return self.linear(x) # 实例化模型
model = LinearSVM(num_features) # 定义损失函数和优化器
criterion = nn.HingeEmbeddingLoss() # 使用合页损失作为SVM的损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 训练模型
num_epochs = 1000
for epoch in range(num_epochs): # 前向传播 outputs = model(X_train) loss = criterion(outputs.squeeze() * y_train, torch.ones_like(y_train)) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 100 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}') # 使用训练好的模型进行预测
with torch.no_grad(): y_pred = model(X_test).squeeze() y_pred_class = (y_pred > 0).float() accuracy = accuracy_score(y_test.numpy(), y_pred_class.numpy()) print(f'Test Accuracy: {accuracy * 100:.2f}%') # 打印权重作为条件影响力的近似
for i, weight in enumerate(model.linear.weight.data.squeeze().numpy()): print(f"Condition {i+1} influence: {weight}")在这个例子中,我们使用了HingeEmbeddingLoss作为损失函数,它是SVM中常用的合页损失的一种变体。模型的权重在训练过程中被调整以最小化这个损失。在训练完成后,我们打印了线性层的权重,这些权重可以被解释为每个条件对最终决策的影响力的一种近似。然而,请注意,这种解释是基于线性模型的,且实际影响力可能更加复杂。
示例二
支持向量机(SVM)是一种用于分类、回归和异常值检测的非概率二元线性分类器。在SVM中,模型尝试在高维空间中找到一个超平面,以最大化地将不同类别的样本分隔开。然而,标准的SVM模型并不直接提供特征重要性或影响力的度量。
尽管如此,我们可以通过观察训练后的SVM模型中特征的权重来大致估计每个特征对分类决策的影响力。在线性SVM中,每个特征都有一个对应的权重,这个权重可以被认为是该特征对分类决策的影响力的一种表示。对于非线性SVM(如使用核技巧的SVM),特征的影响力则不那么直接,因为输入空间被映射到了一个更高维的特征空间。
PyTorch没有内置的SVM实现,但我们可以使用其他库,如scikit-learn,来训练一个SVM模型并检查特征的权重。不过,如果坚持要使用PyTorch来构建类似SVM的模型,我们可以实现一个简单的线性SVM,并检查权重以估计特征的影响力。
下面是一个使用PyTorch构建线性SVM并打印特征影响力的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 假设我们有5个条件(特征)
num_features = 5 # 生成一些模拟数据
X, y = make_classification(n_samples=100, n_features=num_features, n_informative=num_features, n_redundant=0, random_state=42)
X = torch.tensor(X.astype(float))
y = torch.tensor(y.astype(float).reshape(-1, 1)) # Reshape to match PyTorch expectations # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 定义线性SVM模型
class LinearSVM(nn.Module): def __init__(self, input_dim): super(LinearSVM, self).__init__() self.fc = nn.Linear(input_dim, 1) def forward(self, x): return self.fc(x) # 实例化模型
model = LinearSVM(num_features) # 定义损失函数和优化器
criterion = nn.HingeEmbeddingLoss() # SVM通常使用合页损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 训练模型
num_epochs = 1000
for epoch in range(num_epochs): # 前向传播 outputs = model(X_train) loss = criterion(outputs.squeeze(), y_train.squeeze()) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 100 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}') # 评估模型
with torch.no_grad(): predictions = (model(X_test).squeeze() > 0).float() accuracy = accuracy_score(y_test.numpy(), predictions.numpy()) print(f'Test Accuracy: {accuracy}') # 打印特征的影响力(权重的绝对值)
for i, weight in enumerate(model.fc.weight.data.numpy().flatten()): print(f"Condition {i+1} influence: {abs(weight)}")在这个例子中,我们定义了一个简单的线性模型,它只有一个全连接层,没有激活函数。我们使用合页损失(HingeEmbeddingLoss),它是SVM中常用的损失函数。训练完成后,我们打印出全连接层的权重,作为每个条件对最终决策影响力的估计。
请注意,这个例子中的“影响力”是通过打印权重的绝对值来计算的。权重的符号表示特征对分类决策的方向(正或负),而绝对值可以大致表示特征的重要性。然而,这只是一个简单的估计,并不考虑特征之间的相互作用或模型的非线性(在这个例子中是线性的)。
对于非线性SVM或更复杂的模型,可能需要使用其他方法来估计特征的重要性,例如排列特征重要性或基于模型解释的库,如SHAP(SHapley Additive exPlanations)。

该程序在尝试使用 PyTorch 实现一个简单的线性支持向量机(SVM),并在模拟数据上训练它。PyTorch通常要求所有的计算都在同一种数据类型上执行,通常是Float类型,而这里遇到的错误提示表明是在尝试将Double类型的张量输入到期望Float类型的模型中。
要解决此问题,我们应当确保输入到模型中的所有张量都是Float类型。在代码中,可以通过调用`.float()`方法来实现。具体地,可以在创建`X`和`y`的张量时,将它们转换为Float类型。
以下是修正后的代码:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 假设我们有5个条件(特征)
num_features = 5# 生成一些模拟数据
X, y = make_classification(n_samples=100, n_features=num_features, n_informative=num_features, n_redundant=0, random_state=42)# 确保X和y是float类型,以兼容PyTorch
X = torch.tensor(X).float() # cast to float
y = torch.tensor(y).float().view(-1, 1) # cast to float and reshape to match PyTorch expectations# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义线性SVM模型
class LinearSVM(nn.Module):def __init__(self, input_dim):super(LinearSVM, self).__init__()self.fc = nn.Linear(input_dim, 1)def forward(self, x):return self.fc(x)# 实例化模型
model = LinearSVM(num_features)# 定义损失函数和优化器
criterion = nn.HingeEmbeddingLoss() # SVM通常使用合页损失
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')# 评估模型
with torch.no_grad():predictions = (model(X_test).squeeze() > 0).float()accuracy = accuracy_score(y_test.numpy(), predictions.numpy())print(f'Test Accuracy: {accuracy}')
# 打印特征的影响力(权重的绝对值)
for i, weight in enumerate(model.fc.weight.data.numpy().flatten()):print(f"Condition {i+1} influence: {abs(weight)}")注意:在`X = torch.tensor(X).float()`和`y = torch.tensor(y).float().view(-1, 1)`中,移除了对`astype(float)`的调用,因为`.float()`已经确保了张量的类型为float,并且`view()`方法被用于将`y`的形状重新塑造为PyTorch期望的形状,即一个列向量。
这段代码应该能够在不会产生任何类型错误的情况下运行。还可以根据需要调整损失函数(例如在SVM中通常使用合页损失,但可能需要合适的输出转换)和其他超参数。

示例三
支持向量机(SVM)是一种监督学习模型,通常用于分类和回归分析。在SVM中,每个输入特征(本例中的5个条件)对分类边界的位置有影响,但这种影响不是直接通过权重来表示的,而是通过支持向量和核函数来定义的。因此,与神经网络不同,SVM没有直接的“权重”来表示特征的重要性。
然而,线性SVM有一个权重向量,它与输入特征相乘以做出决策。这些权重可以解释为特征对分类决策的影响力。对于非线性SVM,特征的影响力不那么直接,因为它们被映射到一个高维空间,其中非线性决策边界被构造。
在PyTorch中,我们可以使用TorchSVM这样的第三方库来实现SVM,或者使用标准库来实现线性SVM的简化版本。但是,请注意,PyTorch本身并没有提供官方的SVM实现。
为了简化问题,我们可以实现一个线性SVM,并解释其权重作为特征的影响力。这里是一个简单的例子,演示如何使用PyTorch构建一个线性SVM模型,并打印出5个条件的影响力(权重):
import torch
from torch import nn
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score # 生成模拟数据
np.random.seed(42)
X, y = make_classification(n_samples=100, n_features=5, n_informative=5, n_redundant=0, random_state=42)
X_tensor = torch.tensor(X.astype(np.float32))
y_tensor = torch.tensor(y.astype(np.float32)).view(-1, 1) # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_tensor, y_tensor, test_size=0.2, random_state=42) # 将标签转换为±1(SVM标准形式)
y_train = y_train * 2 - 1
y_test = y_test * 2 - 1 # 定义线性SVM模型
class LinearSVM(nn.Module): def __init__(self, input_dim): super(LinearSVM, self).__init__() self.linear = nn.Linear(input_dim, 1) def forward(self, x): return self.linear(x) # 实例化模型
model = LinearSVM(5) # 定义损失函数和优化器
criterion = nn.HingeEmbeddingLoss() # SVM通常使用合页损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 训练模型
num_epochs = 1000
for epoch in range(num_epochs): # 前向传播 outputs = model(X_train) loss = criterion(outputs.squeeze() * y_train.squeeze(), torch.ones_like(y_train)) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 100 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}') # 测试模型
y_pred = model(X_test).squeeze()
y_pred_class = (y_pred > 0).float() * 2 - 1 # 将预测值转换为±1
accuracy = accuracy_score(y_test.numpy(), y_pred_class.detach().numpy())
print(f'Test Accuracy: {accuracy}') # 打印特征的影响力(权重)
for i, weight in enumerate(model.linear.weight.data.squeeze().numpy()): print(f"Condition {i+1} influence: {weight}")在这个例子中,我们创建了一个简单的线性SVM模型,使用了HingeEmbeddingLoss作为损失函数,它试图将正例和负例分隔开,并最大化间隔。模型训练完成后,我们打印出线性层的权重,这些权重可以被解释为每个条件对最终分类决策的影响力。
请注意,这个例子是一个简化的线性SVM实现,并不适用于所有情况,特别是当数据不是线性可分的时候。对于非线性问题,可能需要使用核方法或其他非线性SVM的实现。但是,这些实现通常不会直接提供特征的“影响力”度量,因为决策边界在高维空间中变得更加复杂。

示例四
支持向量机(SVM)是一种监督学习模型,通常用于分类和回归分析。在SVM中,每个输入特征对模型决策边界的影响是通过特征在训练过程中的权重来体现的。然而,标准的SVM模型并不直接提供每个特征对最终预测结果的直接影响力度量。尽管如此,我们可以通过查看训练后的SVM模型中特征的系数来近似估计它们的重要性。
请注意,PyTorch本身并没有提供SVM模型的直接实现,因为SVM通常不是通过梯度下降和反向传播来训练的,而是使用二次规划来解决的。不过,我们可以使用scikit-learn中的SVC(支持向量分类)来实现SVM,并分析特征的重要性。
但是,如果坚持要使用PyTorch风格的代码,我们可以使用PyTorch的自动梯度功能和优化器来近似实现一个线性SVM。以下是一个简化的线性SVM实现,用于二分类问题,并在训练后打印出每个条件(特征)的影响力:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 确保结果可复现
torch.manual_seed(42) # 生成模拟数据
num_conditions = 5
X, y = make_classification(n_samples=100, n_features=num_conditions, n_informative=num_conditions, n_redundant=0, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1) # 线性SVM模型(没有偏置项)
class LinearSVM(nn.Module): def __init__(self, input_dim): super(LinearSVM, self).__init__() self.linear = nn.Linear(input_dim, 1, bias=False) # 偏置项设置为False def forward(self, x): return self.linear(x) # 实例化模型
model = LinearSVM(num_conditions) # 定义优化器和损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.HingeEmbeddingLoss() # 使用合页损失作为SVM的损失函数 # 训练模型
num_epochs = 1000
for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train_tensor) loss = criterion(outputs.squeeze(), y_train_tensor.squeeze()) loss.backward() optimizer.step() if (epoch + 1) % 100 == 0: print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}') # 测试模型
with torch.no_grad(): y_pred = model(X_test_tensor).squeeze() y_pred_class = (y_pred > 0).float() # 根据输出的正负性判断类别 accuracy = accuracy_score(y_test, y_pred_class.numpy()) print(f'Test Accuracy: {accuracy}') # 打印每个条件的影响力(基于训练后的权重)
for i, weight in enumerate(model.linear.weight.data.squeeze().numpy()): print(f"Condition {i + 1} influence: {weight}")在这个例子中,我们实现了一个简单的线性SVM模型,使用合页损失(Hinge Loss)作为损失函数,并通过随机梯度下降(SGD)进行优化。训练完成后,我们打印出线性层中的权重,这些权重可以被解释为每个条件对最终决策的影响力。请注意,这个实现是为了教学目的而简化的,并没有包括所有SVM可能的功能和优化。
此外,由于PyTorch本身不是为SVM设计的,这个实现可能不是最高效或最准确的。在实际应用中,推荐使用专门为SVM设计的库,如scikit-learn中的SVC。
示例五
在支持向量机(Support Vector Machine, SVM)模型中,特征的影响力通常不是直接通过模型的参数来衡量的,因为SVM的决策边界仅由支持向量决定,而这些支持向量是数据集中的一部分样本,不一定是每个特征都具有代表性的。然而,我们可以通过查看训练好的SVM模型中每个特征在决策函数中的权重来近似估计每个条件的影响力。
不过,值得注意的是,PyTorch本身并没有提供SVM的原生实现,因为SVM通常通过求解二次规划问题来训练,而这与神经网络的前向传播和反向传播机制不同。尽管如此,我们可以使用第三方库(如scikit-learn)来训练SVM,并获取特征权重。如果坚持要在PyTorch环境中实现,我们可以自己编写SVM的训练逻辑,但这通常比较复杂且不是PyTorch的典型用法。
由于想要用PyTorch实现SVM,我会给出一个简化的SVM实现示例,但这主要是为了教学目的,实际应用中建议使用成熟的库(如scikit-learn)。
下面是一个简化的线性SVM的PyTorch实现,它计算了每个特征对决策边界的影响力:
import torch
import torch.nn as nn
import torch.optim as optim # 假设数据维度和标签
num_samples = 100
num_conditions = 5 # 随机生成数据
X = torch.randn(num_samples, num_conditions)
y = torch.randint(low=0, high=2, size=(num_samples, 1)) * 2 - 1 # 生成+1和-1的标签 # 线性SVM模型
class LinearSVM(nn.Module): def __init__(self, input_dim): super(LinearSVM, self).__init__() self.linear = nn.Linear(input_dim, 1) def forward(self, x): return self.linear(x) # 初始化模型
model = LinearSVM(num_conditions) # 定义损失函数和优化器
def hinge_loss(output, target): return torch.mean(torch.max(torch.zeros_like(output), 1 - target * output)) optimizer = optim.SGD(model.parameters(), lr=0.01) # 训练模型
num_epochs = 1000
for epoch in range(num_epochs): optimizer.zero_grad() output = model(X) loss = hinge_loss(output, y) loss.backward() optimizer.step() if (epoch + 1) % 100 == 0: print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}') # 打印权重作为影响力
for i, weight in enumerate(model.linear.weight.data.squeeze()): print(f"Condition {i + 1} influence: {weight.item()}")在这个例子中,我们定义了一个简单的线性SVM模型,它只有一个线性层。我们使用随机生成的数据进行训练,并使用hinge loss作为损失函数。训练完成后,我们打印出线性层的权重,这些权重可以被解释为每个条件对决策边界的影响力。
请注意,这个例子是为了教学目的而简化的,并且可能无法在实际问题中达到最佳性能。在实际应用中,建议使用成熟的机器学习库(如scikit-learn)来训练SVM模型,并获取特征的重要性。在scikit-learn中,可以使用coef_属性来获取线性SVM的特征权重。
相关文章:
支持向量机模型pytorch
通过5个条件判定一件事情是否会发生,5个条件对这件事情是否发生的影响力不同,计算每个条件对这件事情发生的影响力多大,写一个支持向量机模型pytorch程序,最后打印5个条件分别的影响力。 示例一 支持向量机(SVM)是一种…...

轮转数组(力扣)
189. 轮转数组 - 力扣(LeetCode) 189. 轮转数组 题解 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 样例输入 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮…...

批量插入10w数据方法对比
环境准备(mysql5.7) CREATE TABLE user (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 唯一id,user_id bigint(10) DEFAULT NULL COMMENT 用户id-uuid,user_name varchar(100) NOT NULL COMMENT 用户名,user_age bigint(10) DEFAULT NULL COMMENT 用户年龄,create_time time…...

HAL STM32 I2C方式读取MT6701磁编码器获取角度例程
HAL STM32 I2C方式读取MT6701磁编码器获取角度例程 📍相关篇《Arduino通过I2C驱动MT6701磁编码器并读取角度数据》🎈《STM32 软件I2C方式读取MT6701磁编码器获取角度例程》📌MT6701当前最新文档资料:https://www.magntek.com.cn/u…...
如何排查nginx服务启动情况,杀死端口,以及防火墙开放指定端口【linux与nginx排查手册】
利用NGINX搭建了视频服务,突然发现启动不了了,于是命令开始 使用以下命令查看更详细的错误信息: systemctl status nginx.service Warning: The unit file, source configuration file or drop-ins of nginx.service changed on disk. Run…...
用Rust实现免费调用ChatGPT的命令行工具 (一)
代码已经开源:🚀 fgpt 欢迎大家star⭐和fork 👏 ChatGPT现在免费提供了GPT3.5的Web访问,不需要注册就可以直接使用,但是,它的使用方式是通过Web页面,不够方便。 更多技术分享关注 入职啦&…...
mysql 查询实战1-题目
学习了mysql 查询实战-变量方式-解答-CSDN博客,接着练习sql,从实战中多练习。 1,题目: 1,查询部门工资最高的员工 1,建表: DROP TABLE IF EXISTS department; create table department(dept_i…...

Word学习笔记之奇偶页的页眉与页码设置
1. 常用格式 在毕业论文中,往往有一下要求: 奇数页右下角显示、偶数页左下角显示奇数页眉为每章标题、偶数页眉为论文标题 2. 问题解决 2.1 前期准备 首先,不论时要求 1、还是要求 2,这里我们都要做一下设置: 鼠…...

数据赋能(58)——要求:数据赋能实施部门能力
“要求:数据赋能实施部门能力”是作为标准的参考内容编写的。 在实施数据赋能中,数据赋能实施部门的能力体现在多个方面,关键能力如下图所示。 在实施数据赋能的过程中,数据赋能实施部门应具备的关键能力如下。 理性思维与逻辑分…...
Unity URP PBR_Cook-Torrance模型
Cook-Torrance模型是一个微表面光照模型,认为物体的表面可以看作是由许多个理想的镜面反射体微小平面组成的。 单点反射镜面反射漫反射占比*漫反射 漫反射 基础色/Π 镜面反射DFG/4(NV)(NL) D代表微平面分布函数,描述的是法线与半角向量normalize(L…...
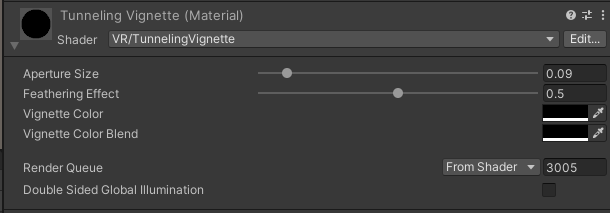
Unity之XR Interaction Toolkit如何在VR中实现渐变黑屏效果
前言 做VR的时候,有时会有跳转场景,切换位置,切换环境,切换进度等等需求,此时相机的画面如果不切换个黑屏,总会感觉很突兀。刚好Unity的XR Interaction Toolkit插件在2.5.x版本,出了一个TunnelingVignette的效果,我们今天就来分析一下他是如何使用的,然后我们自己再来…...
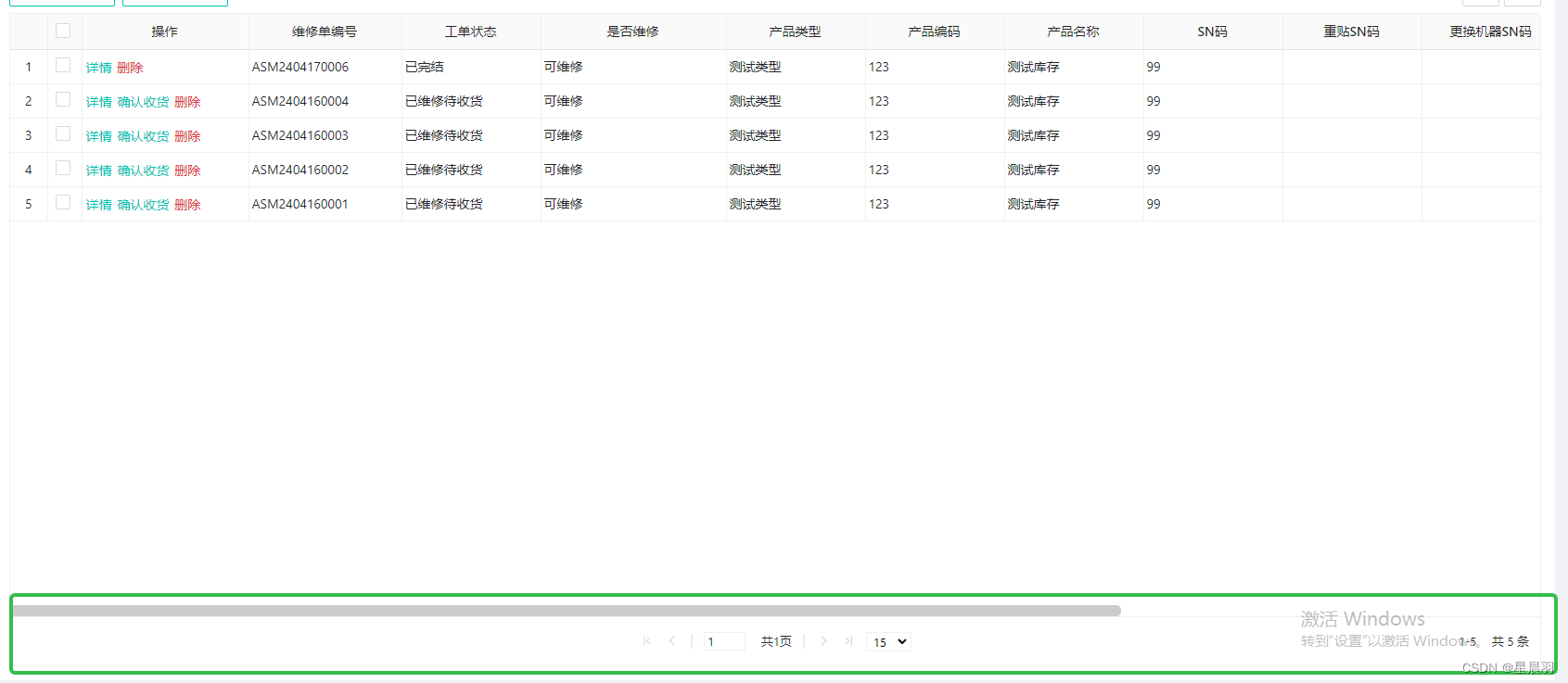
html+vue编写分页功能
效果: html关键代码: <div class"ui-jqgrid-resize-mark" id"rs_mlist_table_C87E35BE"> </div><div class"list_component_pager ui-jqgrid-pager undefined" dir"ltr"><div id"pg…...
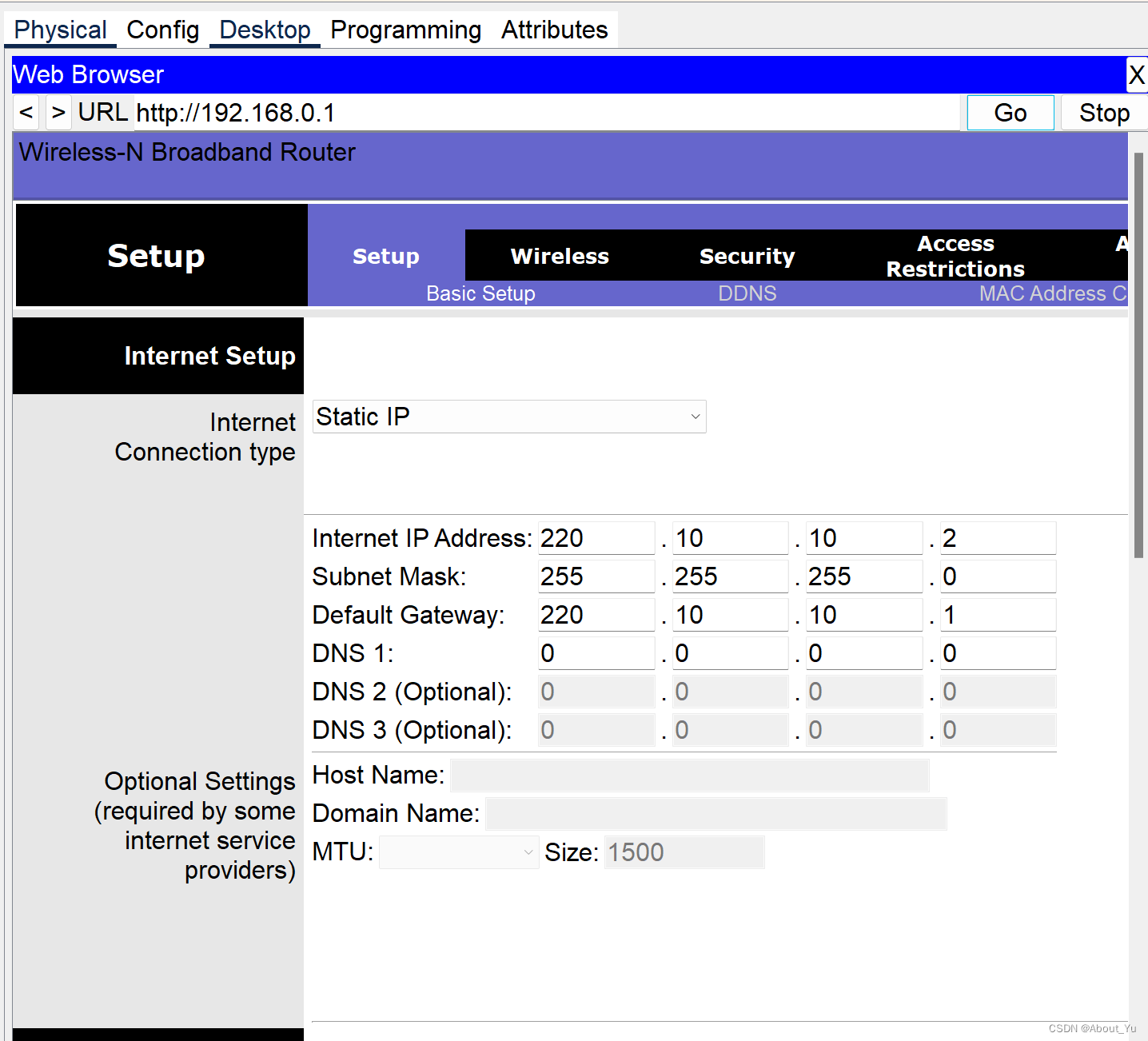
计算机网络 实验指导 实验17
实验17 配置无线网络实验 1.实验拓扑图 Table PC0 和 Table PC1 最开始可能还会连Access Point0,无影响后面会改 名称接口IP地址网关地址Router0fa0/0210.10.10.1fa0/1220.10.10.2Tablet PC0210.10.10.11Tablet PC1210.10.10.12Wireless互联网220.10.10.2LAN192.16…...
在 Vue中,v-for 指令的使用
在 Vue中,v-for 指令用于渲染一个列表,基于源数据多次渲染元素或模板块。它对于展示数组或对象中的数据特别有用。 数组渲染 假设你有一个数组,并且你想为每个数组元素渲染一个 <li> 标签: <template> <ul>…...
达梦数据库执行sql报错:数据溢出
数据库执行sql报错数据溢出 单独查询对应的数字进行计算是不是超过了某个字段类型的上限或下限 如果已经超过了,进行对字段进行cast类型转换处理,转换为dec num都可以尝试 这里就是从 max(T.BLOCK_ID as dec*8192t.bytes)/1024/1024 max_MB,换成了这个…...
从「宏大叙事」到「生活叙事」,小红书品牌种草的的“正确姿势”
不同于抖音和微博,在小红书上,品牌营销的基调应该是怎样的?品牌怎样与小红书用户对话?什么样的内容,才能走进小红书用户的心中?本期,小编将带大家洞察品牌在小红书营销的“正确姿势”。从「小美…...
Python Selenium 的基本使用方法
文章目录 1. 概述2. 安装Chrome及ChromeDriver2.1 安装Chrome2.2 安装ChromeDriver 3. 安装Selenium4. 常见用法4.1 启动4.2 查找元素4.3 等待页面加载元素 1. 概述 Selenium 是一个用于自动化 web 浏览器的工具,它提供了一套用于测试 web 应用程序的工具和库。Sel…...
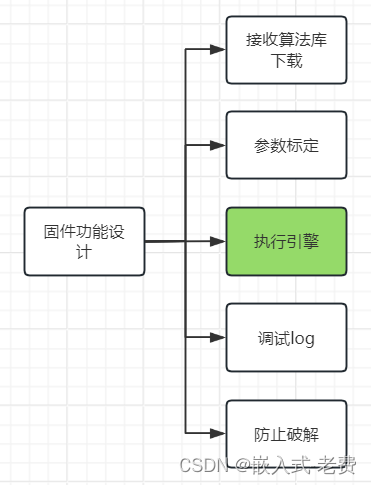
上位机图像处理和嵌入式模块部署(树莓派4b固件功能设计)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 前面我们说过,上位机的功能都是基于插件进行开发的。但是上位机的成本比较贵,一般的企业不一定愿意接接受。这个时候另外一…...
新手入门人工智能:从零开始学习AI的正确途径
你是否对人工智能(AI)充满了好奇心和探索欲?你是否想了解如何从零开始学习AI,成为一名人工智能领域的专家?那么,这篇文章就是为你准备的!我们将带你了解人工智能的基本概念,学习如何…...
ubuntu git相关操作
1 安装git sudo apt install git git --version git version 2.25.1 2 解决git超时 2.1 扩大post的buffer git config --global http.postBuffer 524288000 git config --global http.postBuffer 157286400 2.2 换回HTTP1上传。上传之后再切换回HTTP2 …...
IDEA工具|添加 GitLab 账户之两三事
📫 作者简介:「六月暴雪飞梨花」,专注于研究Java,就职于科技型公司后端工程师 🏆 近期荣誉:华为云云享专家、阿里云专家博主、腾讯云优秀创作者、ACDU成员 🔥 三连支持:欢迎 ❤️关注…...
蓝桥杯:棋盘(Java)
目录 问题描述输入格式输出格式代码实现 问题描述 小蓝拥有n n大小的棋盘,一开始棋盘上全都是白子。小蓝进行了m.次操作,每次操作会将棋盘上某个范围内的所有棋子的颜色取反(也就是白色棋子变为黑色,黑色棋子变为白色)。请输出所…...
跨界融合:ERP与TMS的区分、相通之处、融合方式,全告诉你。
Hi,如今系统的边界越来越模糊,A系统和B系统会有一些功能的交叉,贝格前端工场今天开始介绍第二篇ERP和TMS的融合。 一、什么是ERP和TMS ERP是企业资源规划(Enterprise Resource Planning)的缩写,是一种集成…...
SAP Smartform转存PDF方法汇总
用户会有保存SF至本地PDF文件的需求,下面详细说明一下Smartform转成PDF的四种方法,其中,方法二和三相比于其他方法更便捷实用,如果还有其他方法,欢迎留言补充。 一、代码开发 1)先调用smartform函数获取OTF格式数据 2)后调用函数CONVERT_OTF转换成PDF格式数据 3)再…...

Linux【实战篇】—— NFS服务搭建与配置
目录 一、介绍 1.1什么是NFS? 1.2客户端与服务端之间的NFS如何进行数据传输? 1.3RPC和NFS的启动顺序 1.4NFS服务 系统守护进程 二、安装NFS服务端 2.1安装NFS服务 2.2 创建共享目录 2.3创建共享目录首页文件 2.4关闭防火墙 2.5启动NFS服务 2.…...
Edge的使用心得与深度探索
Microsoft Edge 是微软推出的一款网页浏览器,基于 Chromium 开源项目开发。从 2020 年开始,Edge 浏览器经历了一次重大更新,采用了与 Google Chrome 相同的浏览器引擎,这使得它在性能、兼容性和扩展支持方面都得到了显著改善。以下…...
逆向案例二十八——红某点集登录接口逆向序
网址:aHR0cHM6Ly93d3cuaHJkanl1bi5jb20vIy9sb2dpbj9yZWRpcmVjdD0lMkZyZWFsVGltZUxpdmluZw 登录接口,发现两个参数加密,分别是pwd和sig,t很明显是时间戳。 观察pwd,发现很像md5加密,我输入的密码是123456,在在线加密网…...
我的创作纪念日20240418
机缘 我的技术博客起源于对编程的深深热爱和对知识的渴望。从一开始,我就被编程世界的无限可能所吸引,而这种热情也推动我开始了技术创作之旅。我创建博客的初衷有以下几点: 分享实战经验:在工作中,我遇到了许多技术…...
计算机视觉入门
计算机视觉是人工智能的一个分支,它涉及研究如何使计算机能够理解和解释图像和视频中的视觉信息。这个领域结合了计算机科学、工程学、神经科学和认知科学等多个学科的知识。以下是计算机视觉入门的一些关键点: 1. 基础概念 - **图像处理**:对…...

CTFHUB-技能树-Web前置技能-文件上传(前端验证—MIME绕过、00截断、00截断-双写后缀)
CTFHUB-技能树-Web前置技能-文件上传(前端验证—MIME绕过、00截断、00截断-双写后缀) 文章目录 CTFHUB-技能树-Web前置技能-文件上传(前端验证—MIME绕过、00截断、00截断-双写后缀)前端验证—MIME绕过有关MIMEMIME的作用 解题时有…...

Java面试题笔记(持续更新)
Java基础 java中的Math.round(-1.5)等于多少? Math的round方法是四舍五入,如果参数是负数,则往大的数如,Math.round(-1.5)-1,如果是Math.round(1.5)则结果为2 JDK和JRE的区别? JDK 是 Java Development ToolKit 的简称,也就是…...
格式化字符串漏洞学习笔记
简单介绍 格式化字符串漏洞和栈溢出有相似之处,但又有所不同,都是利用了程序员的疏忽大意来改变程序运行的正常流程。 1、格式化字符串的介绍 printf()、fprint()等print()系列的函数可以按照一定的格式将数据进行输出。 实例…...
用友NC avatar接口文件上传漏洞
产品简介 用友NC是一款企业级ERP软件。作为一种信息化管理工具,用友NC提供了一系列业务管理模块,包括财务会计、采购管理销售管理、物料管理、生产计划和人力资源管理等,帮助企业实现数字化转型和高效管理。 漏洞介绍 用友 NC avatar接口处…...

【Go语言快速上手(二)】 分支与循环函数讲解
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Go语言专栏⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习更多Go语言知识 🔝🔝 Go快速上手 1. 前言2. 分支与循环2.1…...
动手写sql 《牛客网80道sql》
第1章:SQL编写基础逻辑和常见问题 基础逻辑 SELECT语句: 选择数据表中的列。FROM语句: 指定查询将要从哪个表中检索数据。WHERE语句: 过滤条件,用于提取满足特定条件的记录。GROUP BY语句: 对结果进行分组。HAVING语句: 对分组后的结果进行条件过滤。O…...
Node.js、Java、Python、PHP在构建BS系统时的特点比较
在现代软件开发领域,构建一个稳定、高效的B/S(浏览器/服务器)系统对于企业的信息化发展至关重要。Node.js、Java、Python和PHP是当下流行的几种后端开发技术,它们各自具有独特的特点和优势。本文将对这几种技术在构建B/S系统时的特…...

快速入门深度学习9.1(用时20min)——GRU
速通《动手学深度学习》9.1 写在最前面九、现代循环神经网络9.1 门控循环单元(GRU)9.1.1. 门控隐状态9.1.1.1. 重置门和更新门9.1.1.2. 候选隐状态9.1.1.3. 隐状态 9.1.3 API简洁实现小结 🌈你好呀!我是 是Yu欸 🌌 20…...
基于51单片机的步进电机调速系统设计
基于51单片机的步进电机调速系统 (仿真+程序+原理图+设计报告) 功能介绍 具体功能: 1.按键可以控制电机正、反转,加、减速,停止; 2.一位7段数码管实时显示档位…...
postcss概述
PostCSS是一个用于转换CSS的工具,它使用插件来处理CSS,并提供了一种方式来编写可扩展的CSS代码。其主要特点如下: 插件驱动:PostCSS的核心非常轻量级,大部分功能都是通过插件来实现的。这意味着用户可以根据项目的需求…...
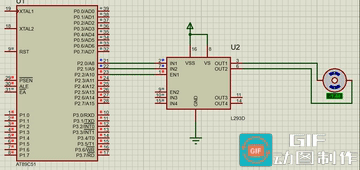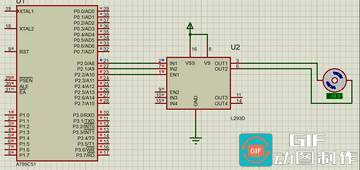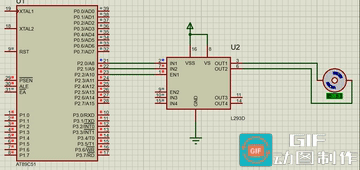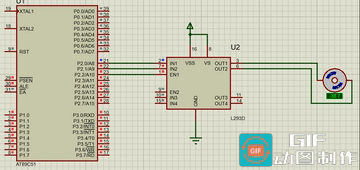
【Proteus】51单片机对直流电机的控制
直流电机:输出或输入为直流电能的旋转电机。能实现直流电能和机械能互相转换的电机。把它作电动机运行时是直流电动机,电能转换为机械能;作发电机运行时是直流发电机,机 械能转换为电能。 直流电机的控制: 1、方向控制…...

JET毛选学习笔记:如何利用《实践论》学习实验
一、个人背景介绍 本人本科读的是预防医学专业(因为没考上临床),硕博连读(报名人少,我报了就得了)的时候专业是流行病与卫生统计学,除了学习流行病学、统计学(忘得差不多了…...

FinalShell 远程连接 Linux(Ubuntu)系统
Linux 系列教程: VMware 安装配置 Ubuntu(最新版、超详细)FinalShell 远程连接 Linux(Ubuntu)系统Ubuntu 系统安装 VS Code 并配置 C 环境 ➡️➡️➡️提出一个问题:为什么使用 FinalShell 连接࿰…...

Python零基础从小白打怪升级中~~~~~~~多线程
线程安全和锁 一、全局解释器锁 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。 GIL全称global interpreter lock,全局解释器锁。 每个线程在执行的时候都需要先获取GIL,保证同一时刻只…...
【机器学习300问】67、均方误差与交叉熵误差,两种损失函数的区别?
一、均方误差(Mean Squared Error, MSE) 假设你是一个教练,在指导学生射箭。每次射箭后,你可以测量子弹的落点距离靶心的差距(误差)。MSE就像是计算所以射击误差的平方后的平均值。它强调了每一次偏离靶心的…...
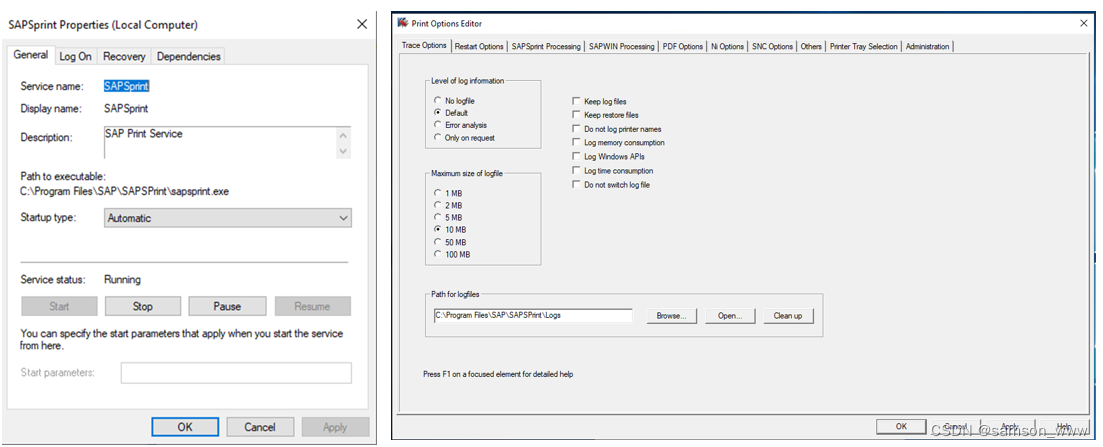
SAP打印输出设置
SAP打印输入有很多方式,适合不同的应用场景。 一.打印输出总体概览图 二.前台打印 这个是比较常见的,前端打印的出现减轻了管理员的工作量,用户可以选择自己电脑上的打印机输出,不需要所有打印机都在SAP平台中进行配置࿰…...
qt对json文件下,qdatetime时间的正确读写方式
qt 对json文件下qdatetime时间的正确读写方式 被搞了很长时间,最后发现是需要控制格式。 正确方式 // read QByteArray localBytes mapJson["playTime"].toString().toLocal8Bit(); char* char_time localBytes.data(); std::string str_time char_…...

【系统分析师】计算机网络
文章目录 1、TCP/IP协议族1.1 DHCP协议1.2 DNS协议1.3网络故障诊断 2、网路规划与设计2.1逻辑网络设计2.2物理网络设计2.3 分层设计 3、网络接入3.1 接入方式3.2 IPv6地址 4、综合布线技术5、物联网5.1物联网概念与分层5.2 物联网关键技术 6、云计算7、网络存储技术(…...
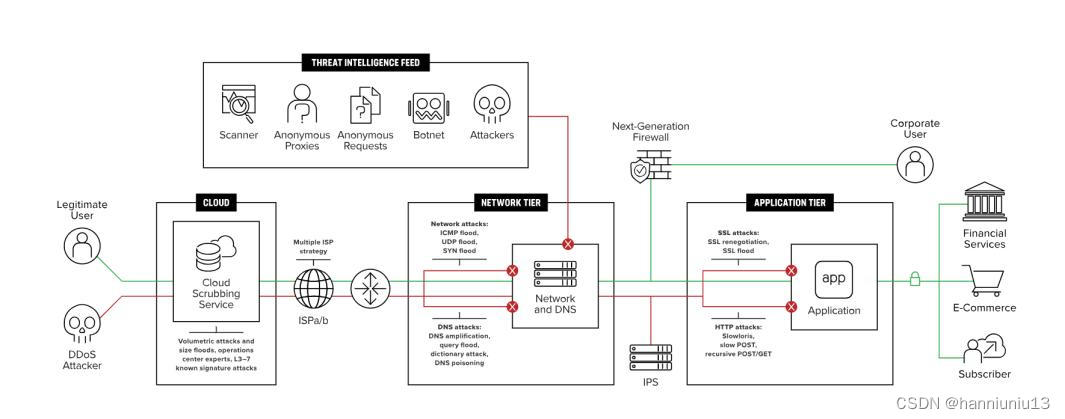
DDoS攻击愈演愈烈,谈如何做好DDoS防御
DDoS攻击是目前最常见的网络攻击方式之一,各种规模的企业包括组织机构都在受其影响。对于未受保护的企业来讲,每次DDoS攻击的平均成本为20万美元。可见,我们显然需要开展更多的DDoS防御工作。除考虑如何规避已发生的攻击外,更重要…...
48.基于SpringBoot + Vue实现的前后端分离-雪具销售系统(项目 + 论文PPT)
项目介绍 本站是一个B/S模式系统,采用SpringBoot Vue框架,MYSQL数据库设计开发,充分保证系统的稳定性。系统具有界面清晰、操作简单,功能齐全的特点,使得基于SpringBoot Vue技术的雪具销售系统设计与实现管理工作系统…...
P8715 [蓝桥杯 2020 省 AB2] 子串分值 (双边检测)
# [蓝桥杯 2020 省 AB2] 子串分值 ## 题目描述 对于一个字符串 $S$, 我们定义 $S$ 的分值 $f(S)$ 为 $S$ 中恰好出现一次的字符个数。例如 $f\left({ }^{\prime \prime} \mathrm{aba}{ }^{\prime \prime}\right)1$,$f\left({ }^{\prime \prime} \mathrm{abc}{ }^{…...